Understanding VAE as a Regularized Autoencoder
Recall that the Variational Autoencoder (VAE) objective is given by:
We can rewrite this as:
Where:
- The first term is the reconstruction error
- The second term acts as a regularizer
This formulation shows that the VAE objective can be interpreted as a regularized autoencoder, where the regularization term encourages the latent distribution to be close to the prior $p(z)$.
Connection to Regularization and MAP Estimation
In regularized empirical risk minimization (ERM), we have:
$$ R_{reg}(\theta) = R(\theta) + \lambda \Omega(\theta) $$
Where:
- $R(\theta)$ is the empirical risk
- $\Omega(\theta)$ is the regularization term
- $\lambda$ is the regularization strength
Regularized ERM can be seen as equivalent to Maximum A Posteriori (MAP) estimation:
$$ R_{reg}(\theta) \sim MAP $$
However, the prior does not need to be on the parameters $\theta$; it can also be on the outputs of an intermediate layer. In the context of VAEs, the KL divergence term acts as a prior on the latent variable $z$.
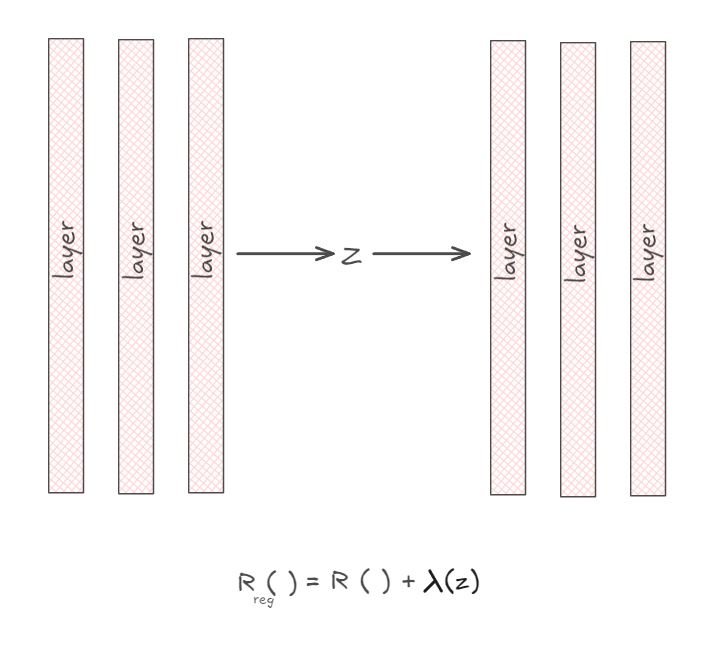
can be seen as a form of regularized ERM with a prior on the output of the latent space.
Beta VAEs
Beta VAEs are an extension of Variational Autoencoders (VAEs) that introduce a hyperparameter $\beta$ to control the trade-off between reconstruction accuracy and latent space regularization. The objective function is given by:
Where:
- The first term is the reconstruction loss, measuring how well the model reconstructs input $x$ from latent $z$
- The second term $D_{KL} \left( q_{\phi}(z|x) | p(z) \right)$ is the KL divergence regularizer ensuring the learned latent distribution matches the prior
- The hyperparameter $\beta$ controls the regularization strength:
- When $\beta = 1$, this reduces to the standard VAE
- When $\beta > 1$, stronger regularization encourages more disentangled latent representations
- When $\beta < 1$, the model prioritizes reconstruction accuracy over prior matching